Study design and setting
This retrospective observational study was carried out in 2024 utilizing the Clear Reporting of a Multivariable Prediction Mannequin for Particular person Prognosis or Prognosis (TRIPOD) guideline (Appendix A). It utilized a dataset comprising 897 sufferers poisoned with methanol, together with data of each sufferers needing intubation and those that didn’t, from Loghman Hakim Hospital in Iran, Tehran. The first goal of this study was to look at the necessity for intubation in methanol-poisoned sufferers. To foretell the need for intubation in methanol-poisoned sufferers, eight established ML and DL models had been deployed. These models leveraged an array of medical and demographic options from the dataset to make correct predictions. To mitigate the danger of overfitting, the coaching of those models included a strong tenfold cross-validation strategy, making certain their generalizability and reliability.
Knowledge set description and members
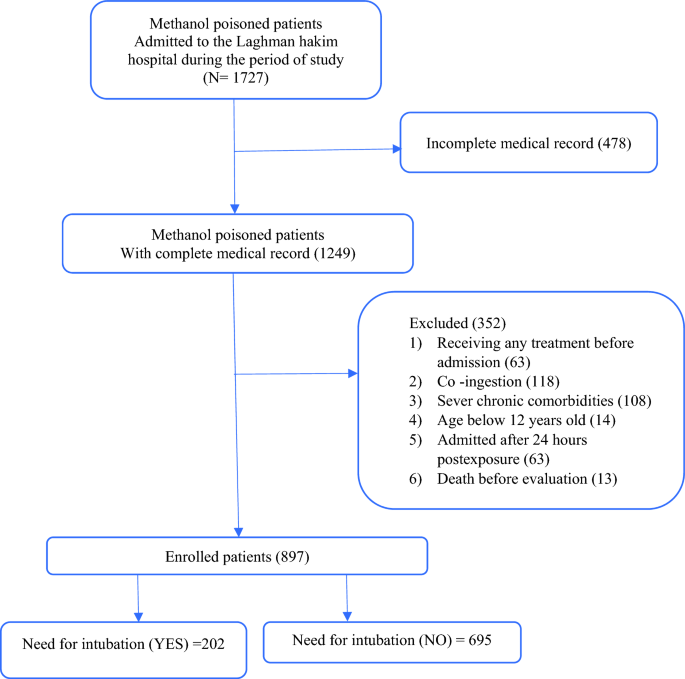
Dataset includes methanol-poisoned sufferers requiring intubation and covers admissions from March 17, 2020, to March 20, 2024. The dataset contains 897 data of sufferers poisoned with methanol from Loghman Hakim Hospital. This hospital acts as the main vacation spot for referrals for people affected by poisoning. Inside this dataset, there have been 202 circumstances of methanol-poisoned sufferers requiring intubation and 695 circumstances of methanol-poisoned sufferers who didn’t require intubation. The affirmation of methanol poisoning concerned reviewing medical data for proof of methanol publicity, serum methanol ranges surpassing 6.25 mmol/L (20 mg/dL), or the manifestation of medical signs similar to visible disturbances, belly ache, respiration difficulties, and neurological signs, alongside a pH stage beneath 7.3 and serum bicarbonate ranges beneath 20 mmol/L upon admission.
The affected person choice course of is depicted in Fig. 1. The study included people aged 12 and above who had been hospitalized inside 24 h of confirmed methanol poisoning. The standards for exclusion included the simultaneous ingestion of gear moreover ethanol, the administration of any pre-admission therapies that may affect the evaluation, extreme continual situations (similar to heart problems, continual kidney illness, continual liver illness, diabetes, continual obstructive pulmonary illness, blood issues, malignancy, and many others.), mortality earlier than evaluation, and incomplete medical documentation. Sufferers had been categorized into two teams: these necessitating intubation and these not requiring it.

Sufferers’ choice flowchart.
It must be famous that there isn’t any particular classification for intubating sufferers poisoned with methanol. Usually, these sufferers are intubated primarily based on medical signs, laboratory findings (similar to blood methanol ranges and metabolic acidosis), and general well being standing. Consequently, in this study, solely the sufferers who met the established medical standards for intubation had been included.
Knowledge assortment
Six particular person researchers carried out a thorough assessment of the sufferers’ medical data. The unique questionnaire, obtained from the digital databases of Loghman Hakim Hospital (Sabara and Shafa databases), was utilized to collect medical knowledge.
This questionnaire encompassed particulars concerning age, gender, important indicators (together with respiratory price, blood strain, physique temperature, and pulse price), medical historical past (together with underlying situations), psychological standing (together with agitation, confusion, seizures, and GCS rating), visible signs upon admission, ingested dose, antidote remedy, and laboratory take a look at outcomes (together with hemoglobin, platelet depend, white cell depend, serum creatinine (sCr), blood glucose, alanine transaminase (ALT), creatine phosphokinase (CPK), aspartate transaminase (AST), sodium, potassium, alkaline phosphatase (ALP), venous blood fuel evaluation (pH, PCO2, and HCO3), and blood urea nitrogen (BUN)). Moreover, hospital-related elements similar to the requirement for intubation and length of hospitalization had been recorded.
Pre-processing of the knowledge
To organize the knowledge for evaluation, we started by importing the dataset into Jupyter Pocket book inside the Anaconda atmosphere, using Python model 13.1. For efficient knowledge preprocessing, we relied on the NumPy library, important for dealing with array operations and mathematical features. NumPy facilitates numerous preprocessing duties, similar to managing lacking values and conducting statistical calculations, which streamline knowledge manipulation and pave the means for deeper evaluation. Initially, lacking values of sure variables had been changed with imply and mode statistical measures. Subsequently, nominal values of variables in the columns had been transformed to numerical values for improved outcomes, using variable encoding to boost algorithm learning. Lastly, incomplete rows of knowledge (with lacking values exceeding 70%) had been eliminated. This systematic strategy ensured that our dataset was clear and prepared for evaluation, minimizing the potential for biased outcomes and enhancing the reliability of our findings.
Afterwards, we utilized Min–max normalization to the knowledge. This concerned figuring out and eradicating outliers from the dataset to boost its high quality. Min–max normalization adjusts numerical knowledge to a predetermined vary, normally 0 and 1, whereas preserving the relative relationships between values. This technique is employed in knowledge normalization to foster uniform and standardized function scales, stopping sure options from dominating others throughout evaluation. By preserving proportional relationships between values, Min–max normalization ensures equitable comparability and exact interpretation of the dataset throughout numerous options.
Function choice
The primary objective of function choice in machine learning is to pinpoint the finest options or key parameters to boost mannequin efficiency. Amongst 187 evaluated options, 110 had been excluded as a result of incomplete medical data and lacking knowledge. The remaining 77 options underwent Pearson’s correlation coefficient evaluation, ensuing in the identification of 43 important options for predicting methanol poisoning prognosis. Options with near-zero correlation and linear knowledge illustration had been eliminated. These 43 options had been then built-in into machine learning models. Afterwards, the FeatureWiz library was utilized for one other spherical of function choice, resulting in 23 chosen options. Function choice utilizing the FeatureWiz library includes two predominant phases. Initially, the Looking out for the Uncorrelated Checklist of Variables (SULOV) technique identifies variable pairs exterior the correlation threshold. Subsequently, the Mutual Info Rating (MIS) of those pairs is calculated, and the pair with the lowest correlation and highest MIS is chosen for additional evaluation. In the subsequent section, variables chosen by SULOV are iteratively processed by XGboost to establish optimum options primarily based on the goal variable, thus lowering the dataset dimension. This technique helps in deciding on the most impactful predictive options from the dataset.
Knowledge evaluation software program
On this study, we extensively employed the Python programming language (model 13.1) together with numerous related libraries. We utilized Jupyter Pocket book inside the Anaconda atmosphere, using Python model 13.1. Matplotlib, NumPy, Seaborn, and Pandas had been utilized for knowledge evaluation and visualization, whereas the scikit-learn library facilitated the improvement and analysis of machine learning models Deep learning architectures, had been constructed and skilled utilizing TensorFlow. Moreover, mannequin interpretability and function significance analyses had been carried out utilizing SHAP (SHapley Additive exPlanations), and LIME (Native Interpretable Mannequin-agnostic Explanations).”
Machin learning and deep learning models improvement
In whole, we utilized eight well-known models from each the deep learning (DL) and machine learning (ML) realms for prediction the need for intubation in methanol-poisoned sufferers. Amongst the DL models employed had been the Deep Neural Community (DNN), feedforward neural community (FNN), Lengthy Quick-Time period Reminiscence (LSTM), and Convolutional Neural Community (CNN). Conversely, the ML models encompassed Excessive Gradient Boosting (XGB), Assist Vector Machine (SVM), Choice Tree (DT), and an extra Random Forest (RF).
These chosen models provide a numerous array of methodologies appropriate for ailments prediction, encompassing each deep learning and machine learning approaches. Deep learning models like DNN, FNN, LSTM, and CNN excel in capturing intricate patterns inside the knowledge, whereas ML models similar to XGB, SVM, DT, and RF present strong and simply interpretable predictions. By leveraging this vary of models, our goal was to boost prediction accuracy and acquire insights into the complicated elements influencing the need for intubation in methanol-poisoned sufferers.
It must be famous that, whereas it’s true that CNNs are predominantly used for picture knowledge as a result of their means to seize spatial hierarchies, current research9,10 have demonstrated their potential in dealing with tabular knowledge as effectively. CNNs can successfully study native dependencies and patterns inside tabular knowledge, just like how they detect options in photographs. The findings of Buturović et al.’s study9 confirmed that CNNs can carry out precisely in predicting ailments utilizing tabular knowledge.
Cross-validation and hyperparameter tuning
To mitigate the danger of overfitting, we included tenfold cross-validation throughout the coaching of all proposed models. This strategy entails partitioning the dataset into 10 equally sized folds, with the mannequin skilled on 9 folds and validated on the remaining fold in every iteration. This iterative course of is repeated 10 instances to make sure complete validation. The final word efficiency metric is computed by averaging the outcomes from these iterations, providing a reliable analysis of the mannequin’s effectiveness11.
The method of optimizing models for a particular dataset includes the cautious choice and adjustment of hyperparameters to create the simplest mannequin. The choice of hyperparameters performs a essential position in figuring out the general efficiency of a particular machine learning algorithm. After finishing the preprocessing section, a sequence of machine learning (ML) and deep learning (DL) modeling duties had been initiated to fine-tune and optimize these hyperparameters. This iterative strategy was geared in the direction of pinpointing the splendid hyperparameter configurations obligatory for creating models with the highest F-score. On this investigation, we employed the GridSearchCV method to pinpoint the most exact and resilient models. The hyperparameters of the optimum mannequin, the Gradient Boosting Classifier, had been adjusted as follows: (learning_rate = 0.2, max_depth = 5, n_estimators = 10, min_samples_leaf = 30, subsample = 0.8, min_samples_split = 400, random_state = 10, max_features = 9)12.
Rationalization and justification the output of ML and DL models
ML and DL strategies are sometimes considered “black field” models as a result of their intricate inside workings, posing challenges for interpretation13,14.This lack of interpretability might be significantly problematic in important fields like healthcare, the place understanding prediction rationales is significant. To deal with this difficulty, researchers have centered on enhancing mannequin interpretability. Two notable strategies are Shapley Additive Explanations (SHAP) and Native Interpretable Mannequin-agnostic Explanations (LIME), which provide insights into ML mannequin predictions15,16. In our study, each SHAP and LIME had been utilized as interpretability strategies in machine learning. Whereas each strategies serve the objective of explaining mannequin predictions, they’ve distinct traits and can present complementary insights.
SHAP, drawing from Shapley values in cooperative recreation concept, has garnered consideration throughout numerous fields, together with medical research17,18. It assigns contribution values to dataset options, exhibiting their impression on predicted outcomes. These values are derived by comparing predictions with and with out particular options. By analyzing all function combos, SHAP offers a holistic understanding of every function’s contribution, aiding researchers in figuring out their impression on outcomes17. Furthermore, SHAP provides a theoretical framework rooted in cooperative recreation concept, offering globally constant explanations by assigning every function an significance worth primarily based on its contribution to the mannequin’s output. This technique provides a complete understanding of function significance throughout the total dataset19.
LIME is an algorithm aimed toward clarifying predictions made by any classifier or regressor by creating a native interpretable mannequin. It prioritizes interpretability and native constancy, facilitating a qualitative understanding of the enter–output relationship and making certain the mannequin’s reliability close to the predicted occasion. As a model-agnostic instrument, LIME can elucidate any mannequin’s predictions, treating it as a black field. It demonstrates versatility by deciphering picture classifications, offering insights into text-based models, and explaining tabular datasets in numerous codecs textual, numeric, or visible16.
In essence, SHAP and LIME are invaluable for deciphering ML and DL mannequin predictions, boosting transparency and belief in decision-making processes. Their use in healthcare settings aids clinicians in understanding and validating AI predictions, facilitating knowledgeable choices16,20. On this study, SHAP and LIME make clear function influences on predicted outcomes for each ML and DL models. Consequently, SHAP and LIME diagrams had been created for the top-performing mannequin throughout sensitivity, specificity, accuracy, ROC, and F1-score indices.
Due to this fact, by using each SHAP and LIME, we aimed to leverage the strengths of every technique to acquire a extra holistic understanding of our mannequin’s habits. Whereas one technique could suffice in sure situations, the mixed use of SHAP and LIME allowed us to validate and cross-reference the interpretability of our mannequin throughout totally different scales and contexts.
Efficiency analysis of models
The ML and DL models’ efficiency underwent a thorough analysis using efficiency metrics obtained from the confusion matrix, as detailed in Desk 1. The evaluation of predictive models encompassed a vary of important metrics together with accuracy, specificity, sensitivity, F1-score, and the receiver working attribute (ROC) curve, all offered in Desk 2.
Moral concerns
The study obtained approval from the ethics committee of Shahid Beheshti College of Medical Sciences, recognized by reference quantity IR.SBMU.RETECH.REC.1402.826. All strategies had been carried out in accordance with the related pointers and rules by ethics committee of Shahid Beheshti College of Medical Sciences. In circumstances the place members had been unable to supply consent themselves, consent was obtained from members or their households. The knowledgeable consent obtained at our establishments additionally included authorization for potential future retrospective analyses.